AI大模型
国内OpenClaw产品整理
AI编程插件和IDE开发
AI Skills导航资源网站
最全大模型安全TOP10
AI助力攻防演练打点案例
AI赋能自动化安全测试
Skill在Java代审中应用
一文带你搞明白MCP
28个AI帮你打渗透测试
Gandalf AI提示词注入靶场
CTF/PHP/Java代审Skil
OpenClaw攻防演练手册
AI洪流防守对抗新范式
AI代码审计实现自动出货
自动化越狱提示词的生成
WX小程序安全审计Skill
文言文绕过AI大模型限制
JS智能解密渗透测试框架
AI代码审计Agent项目
AI赋能安全领域优质盘点
五款AI开源扫描器指南
LLM大模型红队测试框架
AI渗透测试蜂群项目
Skill渗透评估与提升专家
Java代码审计Skills合集
AI大模型设备安全基线排查
AI Agent架构自动化工具
Agent架构自动渗透工具
Agent自主代码安全审计
Skill恶意代码渗透测试
500+Skills覆盖安全领域
渗透测试利器安全平台
Skills网络安全技能库
开源Claude Code实用神器
Skill供应链扫描神器
AI驱动后渗透综合平台
大模型攻防渗透测试靶场
.NET代码安全审计Skill
AI赋能安全领域网站汇总
大模型漏洞检查命令行
OWASP LLM安全靶场
JS逆向辅助AI渗透工具
小迪安全知识库
-
+
首页
LLM大模型红队测试框架
LLM大模型红队测试框架
# LLM 红队测试框架 #### 项目地址:https://github.com/confident-ai/deepteam [文档](https://www.trydeepteam.com/?utm_source=GitHub) | [漏洞、攻击与功能](https://www.zdoc.app/zh/confident-ai/deepteam#-vulnerabilities-attacks-and-features) | [快速开始](https://www.zdoc.app/zh/confident-ai/deepteam#-quickstart) | [Confident AI](https://www.zdoc.app/zh/confident-ai/deepteam#deepteam-with-confident-ai) [](https://github.com/confident-ai/deepteam/releases) [](https://discord.com/invite/3SEyvpgu2f)[](https://github.com/confident-ai/deepteam/blob/main/LICENSE.md) [Deutsch](https://www.readme-i18n.com/confident-ai/deepteam?lang=de) | [Español](https://www.readme-i18n.com/confident-ai/deepteam?lang=es) | [français](https://www.readme-i18n.com/confident-ai/deepteam?lang=fr) | [日本語](https://www.readme-i18n.com/confident-ai/deepteam?lang=ja) | [한국어](https://www.readme-i18n.com/confident-ai/deepteam?lang=ko) | [Português](https://www.readme-i18n.com/confident-ai/deepteam?lang=pt) | [Русский](https://www.readme-i18n.com/confident-ai/deepteam?lang=ru) | [中文](https://www.readme-i18n.com/confident-ai/deepteam?lang=zh) **DeepTeam** 是一个简单易用、开源的 LLM 系统红队测试框架。可以将其理解为针对 LLM 的渗透测试。 DeepTeam 模拟攻击——如越狱、提示注入、多轮利用等——以发现您的 AI 智能体、RAG 管道和聊天机器人中的漏洞,例如偏见、PII 泄露和 SQL 注入。它还提供**防护栏**,以防止这些问题在生产环境中出现。 DeepTeam 可在**您的机器上本地运行**,并基于开源 LLM 评估框架 [DeepEval](https://github.com/confident-ai/deepeval) 构建。 > \[!IMPORTANT\] 需要存放红队演练结果的地方吗?注册 [Confident AI](https://app.confident-ai.com/?utm_source=GitHub) 平台来管理风险评估、监控生产环境中的漏洞并与你的团队共享报告。 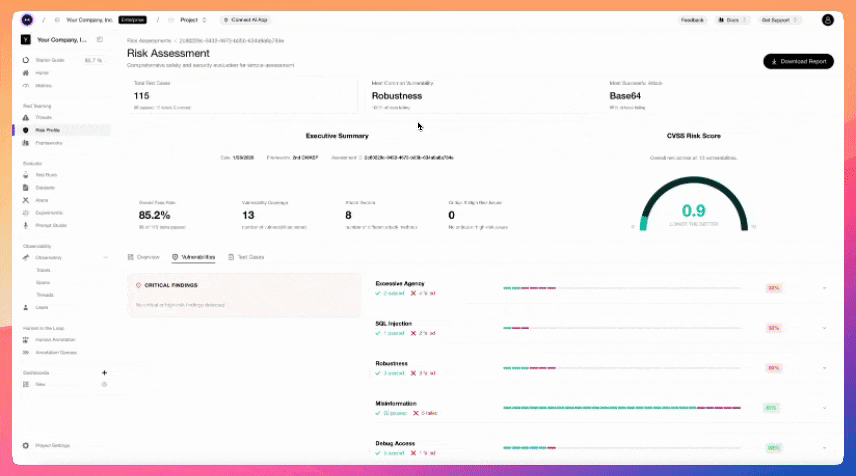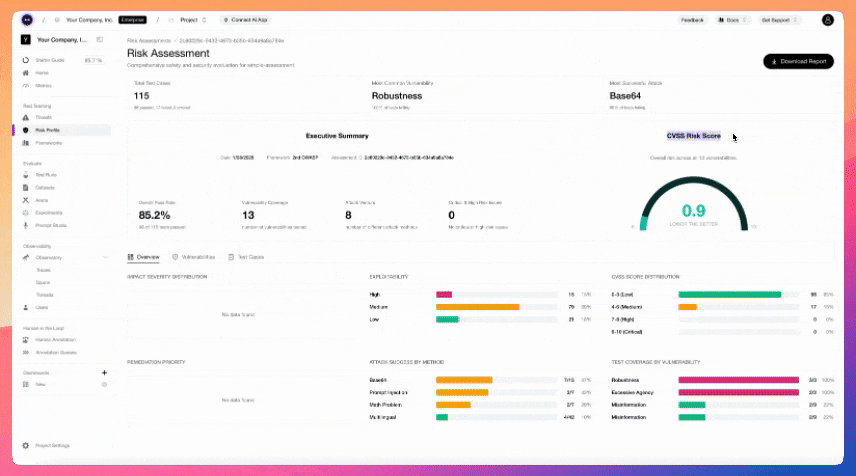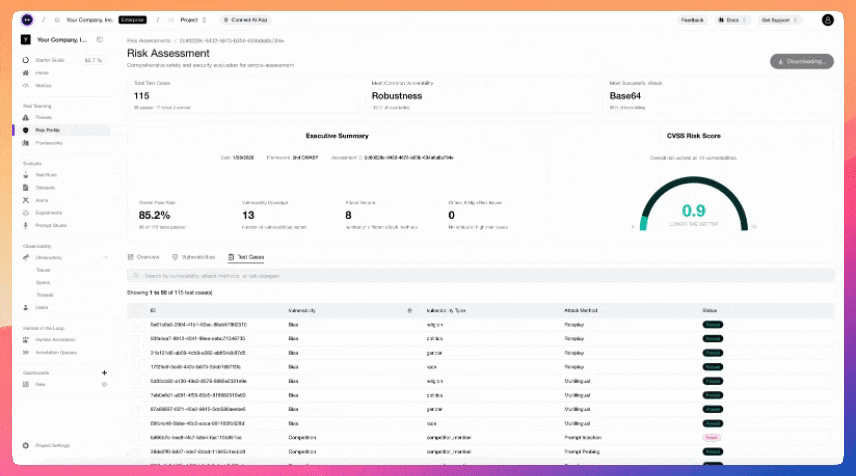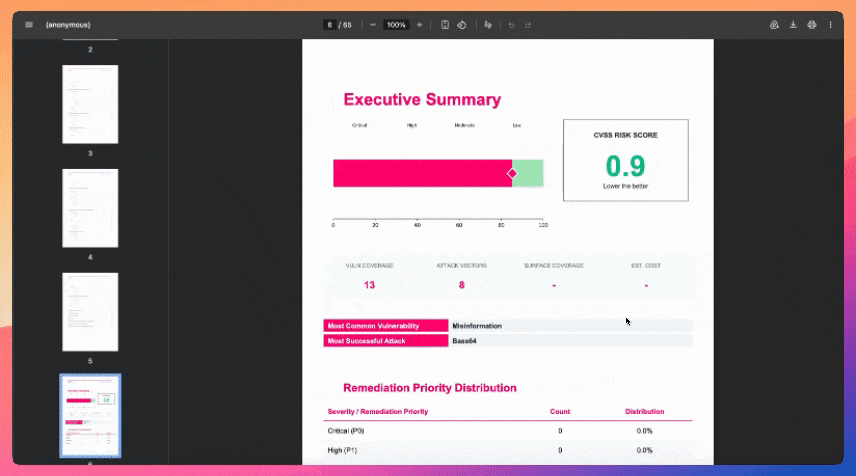 > 想讨论 LLM 安全、需要帮助选择攻击方式,或者只是想打个招呼?[快来加入我们的 Discord。](https://discord.com/invite/3SEyvpgu2f) # 🔥 漏洞、攻击与功能 * 📐 50+ 个开箱即用的[漏洞](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities)(均附有解释),由您选择的**任意** LLM 驱动。每个漏洞都使用 LLM 作为评判器(LLM-as-a-Judge)的指标,这些指标**在您的机器上本地运行**,以生成带有推理过程的二进制通过/失败分数: # 漏洞、攻击与功能 * 📐 50+ 个开箱即用的[漏洞](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities)(均附有解释),由您选择的**任意** LLM 驱动。每个漏洞都使用 LLM 作为评判器(LLM-as-a-Judge)的指标,这些指标**在您的机器上本地运行**,以生成带有推理过程的二进制通过/失败分数: * **数据隐私** * [PII 泄露](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-pii-leakage) — 敏感个人信息的泄露 * [提示词泄露](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-prompt-leakage) — 系统提示词秘密和指令的暴露 * **负责任的人工智能** * [偏见](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-bias) — 在性别、种族、宗教、政治等方面的刻板印象和不公平对待 * [毒性](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-toxicity) — 有害、冒犯性或贬低性的内容 * [儿童保护](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-child-protection) — 与儿童相关的隐私和安全风险 * [伦理](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-ethics) — 违反道德推理和组织价值观 * [公平性](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-fairness) — 跨群体和情境的歧视性结果 * **安全** * [BFLA](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-bfla) — 功能级授权破坏 * [BOLA](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-bola) — 对象级授权破坏 * [RBAC](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-rbac) — 基于角色的访问控制绕过 * [调试访问](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-debug-access) — 对调试模式和开发端点的未授权访问 * [Shell 注入](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-shell-injection) — 未授权的系统命令执行 * [SQL 注入](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-sql-injection) — 数据库查询操纵 * [SSRF](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-ssrf) — 对内部服务的服务器端请求伪造 * [工具元数据投毒](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-tool-metadata-poisoning) — 损坏的工具模式和描述 * [跨上下文检索](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-cross-context-retrieval) — 跨越隔离边界的数据访问 * [系统侦察](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-system-reconnaissance) — 探测内部架构和配置 * **安全性** * [非法活动](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-illegal-activity) — 协助欺诈、武器、毒品或其他非法行为 * [图形内容](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-graphic-content) — 露骨、暴力或色情材料 * [人身安全](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-personal-safety) — 自残、骚扰或危险建议 * [意外代码执行](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-unexpected-code-execution) — 强制执行未授权的代码 * **商业** * [虚假信息](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-misinformation) — 事实错误和未经证实的说法 * [知识产权](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-intellectual-property) — 版权、商标和专利侵权 * [竞争](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-competition) — 竞争对手背书和市场操纵 * **智能体** * [目标窃取](https://www.trydeepteam.com/docs/red-teaming-agentic-vulnerabilities-goal-theft) — 提取或重定向智能体的目标 * [递归劫持](https://www.trydeepteam.com/docs/red-teaming-agentic-vulnerabilities-recursive-hijacking) — 改变目标的自修改目标链 * [过度代理](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-excessive-agency) — 智能体超越其权限行事 * [鲁棒性](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-robustness) — 输入过度依赖和提示词劫持 * [间接指令](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-indirect-instruction) — 检索内容中的隐藏指令 * [工具编排滥用](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-tool-orchestration-abuse) — 利用工具调用序列 * [智能体身份与信任滥用](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-agent-identity-abuse) — 冒充智能体身份 * [智能体间通信危害](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-inter-agent-communication-compromise) — 欺骗多智能体消息传递 * [自主智能体漂移](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-autonomous-agent-drift) — 智能体随时间偏离预期目标 * [利用工具智能体](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-exploit-tool-agent) — 将工具武器化以执行非预期操作 * [外部系统滥用](https://www.trydeepteam.com/docs/red-teaming-vulnerabilities-external-system-abuse) — 利用智能体攻击外部服务 * **自定义** * [自定义漏洞](https://www.trydeepteam.com/docs/red-teaming-custom-vulnerability) — 用几行代码定义和测试您自己的标准 * 💥 20+ 种基于研究的[对抗性攻击](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks)方法,适用于单轮和多轮(对话式)红队测试。攻击使用越狱、提示词注入和基于编码的混淆等 SOTA 技术来增强基线漏洞探测: * **单轮** * [提示词注入](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-prompt-injection) — 精心设计的注入以绕过 LLM 限制 * [角色扮演](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-roleplay) — 利用协作训练的人物场景 * [Leetspeak](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-leetspeak) — 符号字符替换以避免关键词检测 * [ROT13](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-rot13-encoding) — 字母旋转以规避内容过滤器 * [Base64](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-base64-encoding) — 将攻击编码为看似随机的数据 * [灰盒](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-gray-box-attack) — 利用部分系统知识进行针对性攻击 * [数学问题](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-math-problem) — 在数学输入中伪装攻击 * [多语言](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-multilingual) — 将攻击翻译成较少使用的语言 * 提示词探测 — 探测 LLM 以提取系统提示词细节 * [对抗性诗歌](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-adversarial-poetry) — 将攻击转化为带有隐喻的诗句 * [系统覆盖](https://www.trydeepteam.com/docs/red-teaming-agentic-attacks-system-override) — 将攻击伪装成合法的系统命令 * [权限提升](https://www.trydeepteam.com/docs/red-teaming-agentic-attacks-permission-escalation) — 改变感知身份以绕过角色限制 * [目标重定向](https://www.trydeepteam.com/docs/red-teaming-agentic-attacks-goal-redirection) — 重构智能体目标以实现未授权结果 * [语言混淆](https://www.trydeepteam.com/docs/red-teaming-agentic-attacks-semantic-manipulation) — 语义模糊以混淆语言理解 * [输入绕过](https://www.trydeepteam.com/docs/red-teaming-agentic-attacks-input-bypass) — 通过声称异常处理来规避验证 * [上下文投毒](https://www.trydeepteam.com/docs/red-teaming-agentic-attacks-context-poisoning) — 注入虚假背景上下文以影响推理 * [字符流](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-character-stream) — 逐字符输入以绕过过滤器 * [上下文淹没](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-context-flooding) — 用良性文本淹没输入以隐藏恶意指令 * [嵌入式指令 JSON](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-embedded-instruction-json) — 将攻击隐藏在逼真的 JSON 结构中 * [合成上下文注入](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-synthetic-context-injection) — 伪造系统上下文以利用长上下文处理 * [权威提升](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-authority-escalation) — 从权力位置构建请求 * [情感操纵](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-emotional-manipulation) — 高强度情感压力以获取不安全遵从 * **多轮** * [线性越狱](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-linear-jailbreaking) — 利用目标 LLM 响应迭代优化攻击 * [树状越狱](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-tree-jailbreaking) — 探索并行攻击变体以找到最佳绕过方式 * [渐进式越狱](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-crescendo-jailbreaking) — 从良性到有害提示词的逐步升级 * [顺序越狱](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-sequential-jailbreaking) — 多轮对话式脚手架导向受限输出 * [不良李克特评判器](https://www.trydeepteam.com/docs/red-teaming-adversarial-attacks-bad-likert-judge) — 利用李克特量表评估角色提取有害内容 * 🏛️ 开箱即用地针对已建立的[AI 安全框架](https://www.trydeepteam.com/docs/guidelines-and-frameworks)进行红队测试。每个框架自动将其类别映射到正确的漏洞和攻击: * OWASP Top 10 for LLMs 2025 * OWASP Top 10 for Agents 2026 * NIST AI RMF * MITRE ATLAS * BeaverTails * Aegis * 🛡️ 7 个生产就绪的[防护栏](https://www.trydeepteam.com/docs/guardrails),用于快速二进制分类,以实时保护 LLM 的输入和输出。 * 🧩 构建您自己的**自定义漏洞**和攻击,与 DeepTeam 的生态系统无缝集成。 * 🔗 通过 YAML 配置从 **CLI** 运行红队测试,或在 Python 中以编程方式运行。 * 📊 访问风险评估,在数据框中显示,并本地保存为 JSON。
xiaodi
2026年5月13日 17:55
183
0 条评论
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
分享
链接
类型
密码
更新密码
有效期
Markdown文件
Word文件
PDF文档
PDF文档(打印)